Promptfoo is an open source library for evaluating LLM output quality. With Portkey, you can:Documentation Index
Fetch the complete documentation index at: https://portkey-docs-migration-04-ai-tools.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- Manage prompts with versioning and call them in Promptfoo
- Run evals on 1600+ LLMs including private/local models
- Track costs and metrics for all eval runs
- Avoid rate limits with load balancing and caching
1. Reference Portkey Prompts
Use prompts stored in Portkey directly in Promptfoo:- Set
PORTKEY_API_KEYenvironment variable - Use
portkey://prefix with your prompt ID:
Promptfoo doesn’t follow temperature, model, and other parameters set in Portkey. Set them in the providers configuration.
2. Route to Any Provider
SetPORTKEY_API_KEY and configure providers with the portkey: prefix:
Cloud Providers (Azure, Bedrock, Vertex)
3. Track Costs & Metrics
Add metadata to segment requests and track costs per team/project: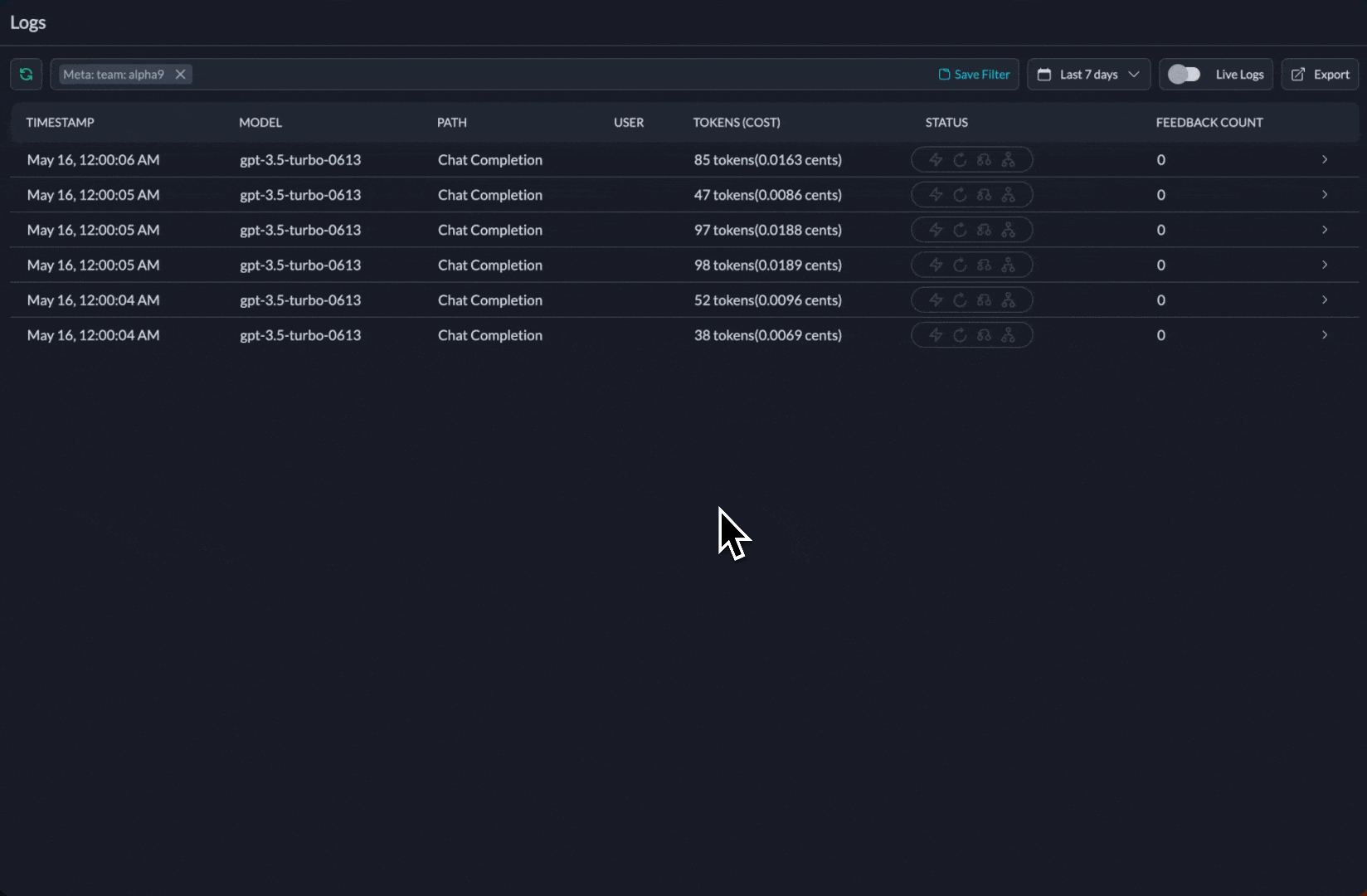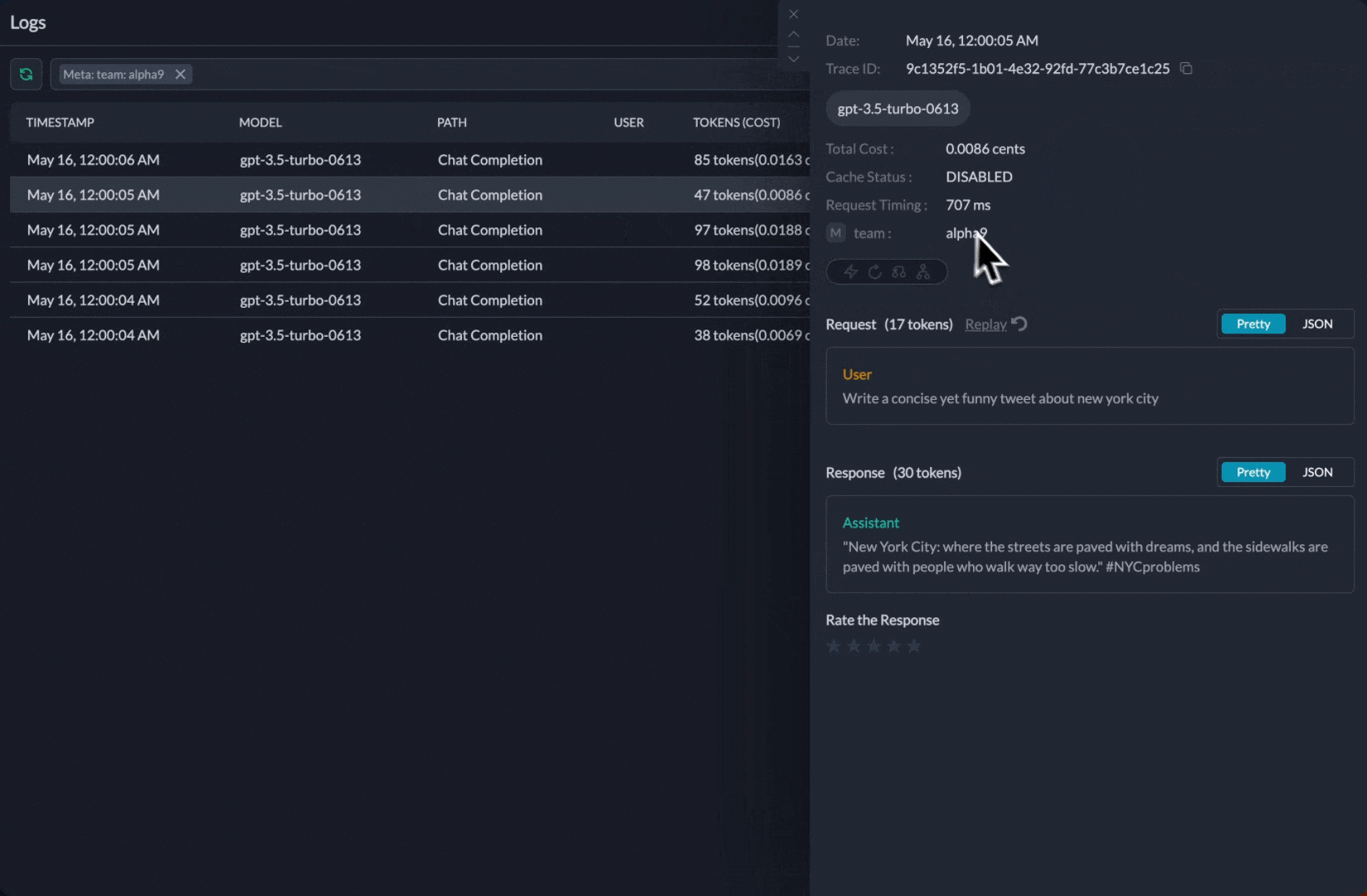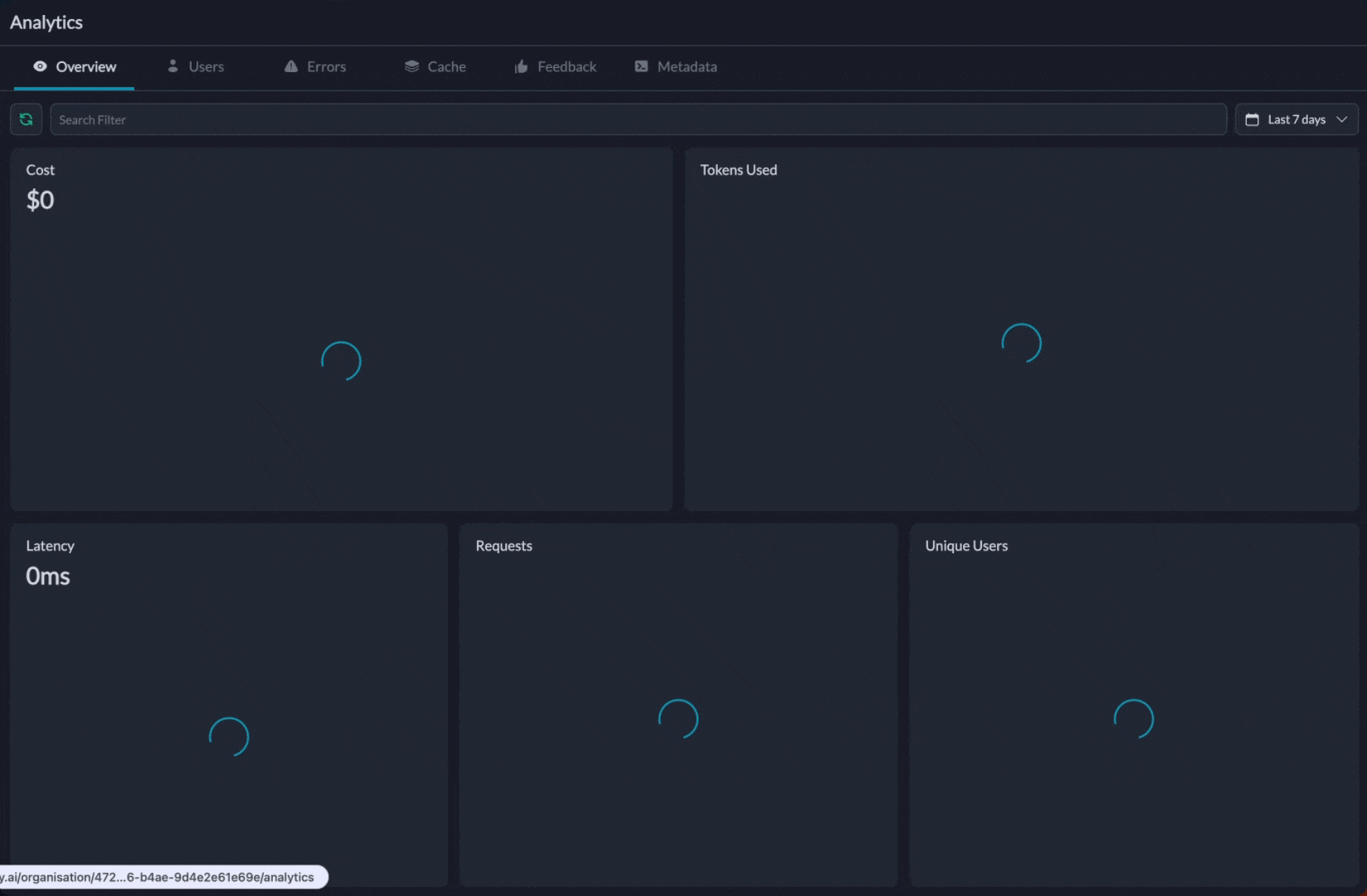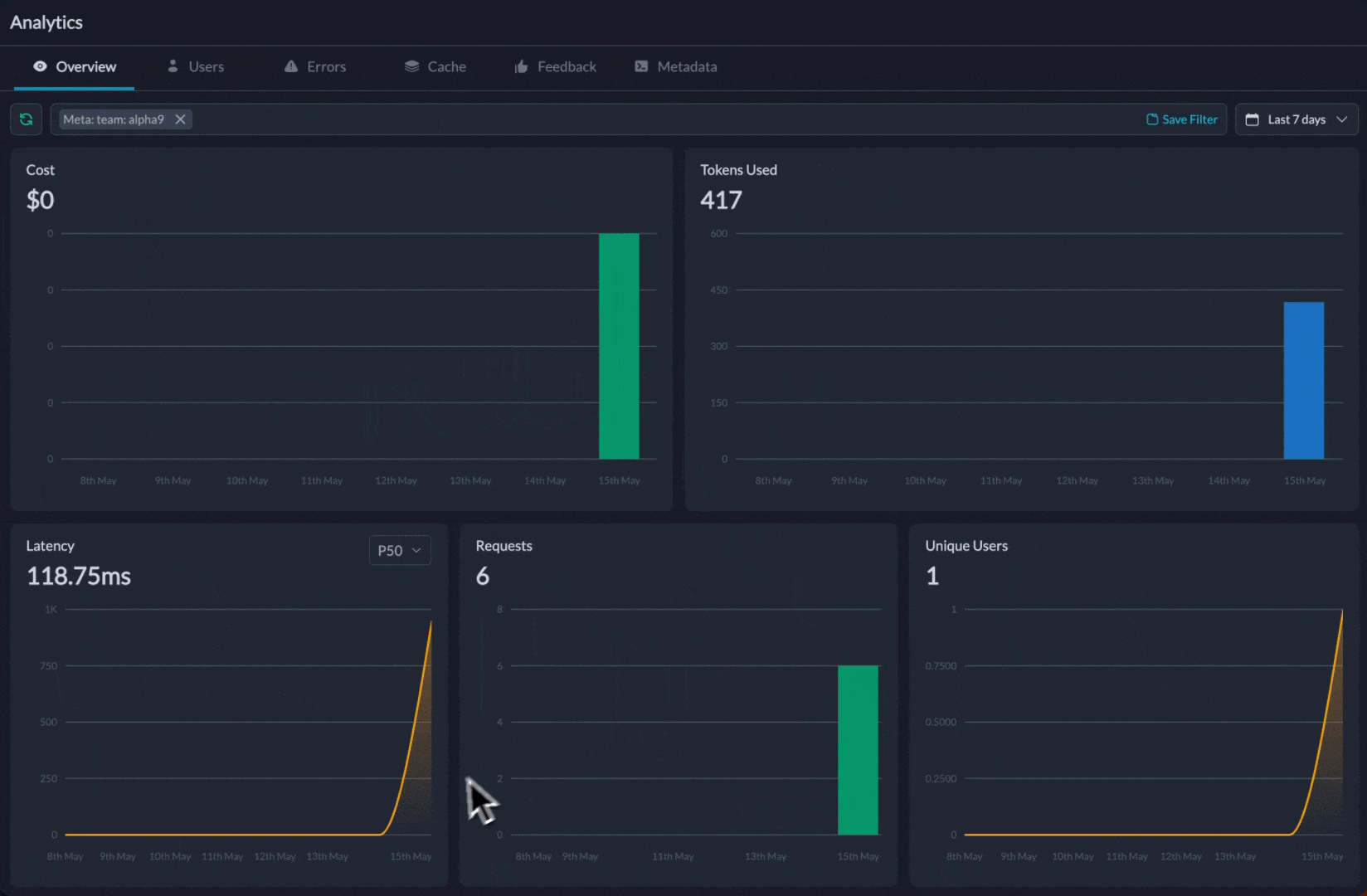
4. Avoid Rate Limits with Caching
Create a config with load balancing and caching for high-volume evals:Roadmap
🚧 Coming soon: View Promptfoo eval results in Portkey’s feedback section.Next Steps
Model Catalog
Set up providers
Prompt Management
Version and manage prompts